Building Mise: A Voice-First Kitchen Agent with Gemini Live
Created for the purposes of entering the Gemini Live Agent Challenge hackathon.
At 6pm every day, millions of people open their fridge and stare into the void.
No plan. No inspiration. Just ingredients and rising hunger.
You had planned to eat healthy and save money, often this moment has you ordering a take-away, blowing your budget and your plan.
We built Mise to solve that moment.
Mise is a voice-first, vision-enabled kitchen companion that sees what ingredients you have, suggests what to cook, and closes the loop to a shopping basket, all using natural conversation.
No typing. No searching. No switching apps.
You talk. Mise listens, looks, and acts.
The Problem: Decision Paralysis in the Kitchen
Recipe apps assume you already know what you want to cook.
Supermarket sites assume you already know what you want to buy.
Neither helps when you are standing in front of your fridge after a long day at work, brain fog in your head and hunger in your belly.
Right now, millions of families are trying to stretch their budget further at every mealtime. The ingredients are there. The intention is there. What’s missing is the moment of inspiration
Mise targets the decision moment before cooking begins.
Why Gemini Live?
At Say It Now we started off building voice first experiences on Alexa and Google Assistant in 2018.
Our vision is to make it possible for every brand to be able to engage in delightful conversations with their customers.
Over the last few years enormous improvements in technology have been made, we have been waiting for Google to something like Gemini Live for us to create experiences that feel alive, not like chatting with a textbox.
Gemini Live made this possible through real-time multimodal streaming.
How We Built It Using Google AI and Google Cloud
Mise runs entirely on Google infrastructure and models.
Core AI Model
We used:
Gemini Live (gemini-live-2.5-flash native audio)
This model handles:
- Real-time speech recognition
- Natural voice generation
- Vision processing from camera input
- Multimodal reasoning
- Conversational continuity
Audio and video stream continuously to the model, allowing the agent to respond without turn-taking delays.
Backend Architecture
Our backend is a lightweight real-time proxy built on Google Cloud.
Stack:
- FastAPI + WebSockets
- Google authentication
- Vertex AI endpoint
- Cloud Run deployment
The browser connects to a Cloud Run service, which streams data to the Gemini Live BidiGenerateContent endpoint.
This architecture enables true live interaction rather than request-response cycles.
The system streams audio and video bidirectionally with no buffering, allowing natural conversation flow .
Token-Driven State Machine
A major challenge with multimodal agents is keeping the UI in sync with the conversation.
We solved this with a token-based state machine.
Mise outputs structured tokens that represent conversation states, for example:
- SCAN — detecting ingredients
- CONFIRM — verifying results
- SUGGEST — proposing recipes
- GAP — identifying missing items
- IMPACT — summarising cost savings
The backend strips these tokens from spoken output and sends them to the frontend as UI triggers.
This allows the conversation itself to drive the interface.
Frontend Experience
The app is delivered as a Progressive Web App hosted on Firebase.
Key design principles:
Voice replaces every tap
There is no search bar or form.
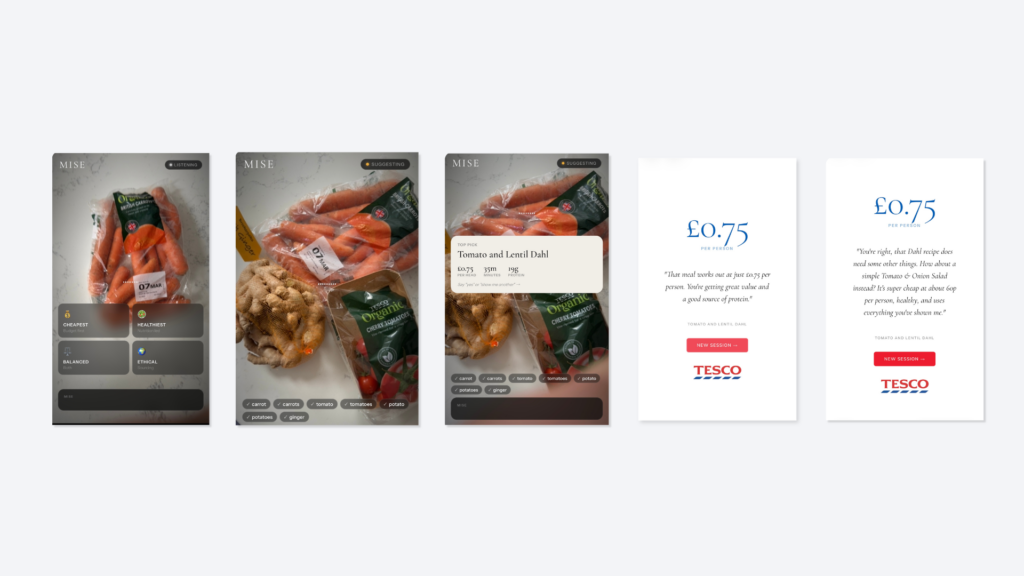
The camera is the interface
Users simply point at ingredients. Vision AI handles detection.
Outputs adapt to priorities
If a user says “cheap,” price leads the recommendation.
If they say “healthy,” nutrition leads.
The goal was a single fluid conversation rather than a sequence of screens.
Example User Flow
- User launches Mise
- Agent asks what matters most: cost, health, or both
- Camera scans ingredients
- Recipes are suggested based on real items detected
- Missing ingredients are identified with prices
- User can add items to a shopping basket
- Agent summarises savings and impact
We believe this is a valuable product for grocery stores and providers we would be delighted to talk to them about commercialisation.
Why This Matters
Voice commerce today is dominated by scripted commands like:
“Alexa, add milk to my basket.”
Mise demonstrates something different: an ambient decision engine that acts before a search begins.
Instead of reacting to a command, it helps form the intention.
This could apply far beyond cooking:
- Retail decision support
- Healthcare triage
- Travel planning
- Education
- Home services
Anywhere people face complex choices in real time.
What We Learned
Multimodal agents require orchestration
Speech, vision, UI, and backend logic must move together. The model alone is not enough.
Latency determines believability
Even small delays break the illusion of conversation.
State management is critical
Without explicit control, agent interactions drift or feel inconsistent.
Iterative prototyping is essential
We evolved the system through rapid build-test cycles, starting from reference implementations and refining continuously.
What Comes Next
Mise is currently a prototype, but the architecture is designed to scale.
Because the system is configurable, it can be white-labelled for different retailers or contexts without rewriting the core agent.
The long-term vision is a universal “intent layer” between people and services.
Hackathon Submission Note
This article was created specifically for the purposes of entering the Gemini Live Agent Challenge hackathon.
Mise is our live agent submission demonstrating how Google AI models and Google Cloud can power real-time multimodal assistants.
Demo and Links
If you are interested in the project, follow our updates as we continue developing the concept.
When sharing this article on social media, we are using the official hashtag:
#GeminiLiveAgentChallenge #MISE